Trying Out OpenCode To Avoid Claude Code Lock-in
I don't want the blog to be flooded with articles about AI tooling, but as I alluded to in my previous post about how the experience with Claude Code is getting worse, I've wanted to try out OpenCode.
Since then in the last couple of days the vibes around Claude continue to sour:
- It looked like Anthropic might be pulling the plug on Claude Code in the Pro tier of the plan, only for the Head of Growth to claim it was a "small test" on 2% of users.
- Claude Code usage might be allowed again in a limited use case for certain agent workflows, but the messaging is very murky.
- There are open issues on unexpectedly high token consumption rate, a bug around auto-compaction, and a regression on the malware reminder on every read
Then Anthropic finally broke the silence with an official response on the drop in quality of Claude Code. The users are still skeptical.
As long as you are given a black box, you have no control and the value of the service can be changed at any time. So of course I want to see if OpenCode can help give a little control back. After all, I'm a big fan of FOSS.
To help me with the evaluation, I put together a post on an experiment I did last month testing out Claude Code by implementing a project I never finished. That means I can run that same experiment again, but with a different harness. Though the question of what model to use needs to be answered first.
On the feasibility of running your own models
Before I can run OpenCode I need to select a model to use. My first thought was to self-host a model, because that is the only way to prevent a service making the model you are using worse.
However, it has been a while since I looked at how well open-weight models were doing. [1] The last time I had tried was Gemma 3 early last year.
I'm not using Opus 4.7 with all the issues currently going on, so I'm mostly curious about how the open models line up with Opus 4.6. Luckily, in the last couple of weeks Kimi K2.6, GLM-5, Qwen 3.6 and Gemma 4 and Deepseek v4 all dropped and have open-weight versions. A quick comparison:
| Model | Released | Parameters | Active Params | Context Size | FP16 Size | INT4 Size | |
|---|---|---|---|---|---|---|---|
| Kimi K2.6 | April 20 | 1T | 32B | 256K | 2TB | 594GB | |
| GLM-5.1 | April 7 | 754B | 40B | 200K | 1.65TB | ||
| Qwen 3.6 | April 16 | 35B | 3B | 263K | 72GB | ||
| Deepseek v4 | April 24 | 1.6T | 49B | 1M | 3.2TB | 800GB | |
| Gemma 4 | April 2 | 30B | 30B | 256K |
The main detail that stood out to me is just how much memory the models need now. Even the quantized version of Kimi is giant.
Yes, there are other, smaller open-weight models like Gemma 4, but not ones that perform on the level of Opus 4.6. [2] So for the purpose of testing OpenCode vs Claude Code with Opus 4.6, I decided to shelve self-hosting for now. Especially considering how high memory and storage prices are currently.
So for this experiment I went with OpenCode's Go subscription. Not because I liked it over other options, but because I could try it for $5 the first month and because they are running a 3x usage limit promo for Kimi K2.6 right now. [3]
Running the experiment
In my previous post I detailed creating a shim to listen to YouTube Music through OpenSubsonic. Take a look at the post if you want to know all the details, but the important parts are:
- I wrote a proof of concept by hand and knew it could be done.
- There was a well defined OpenAPI spec to implement.
- I could use real SubSonic clients to test the implementation as I went.
In terms of actual code produced at the end, I would say OpenCode with K2.6 worked roughly as good as Claude Code with Opus 4.6! With Claude Code I was able to get a working version within a short evening. Though I bumped into a 4-hour window limit once and had to wait ~30 minutes during the process.
In both experiments after generating the stubbed endpoints I cleared the context and asked the tool to compare the generated code to the spec. Both Claude Code and OpenCode made mistakes in their initial generation, but then caught them during that review. [4]
There were also some small implementation details that tripped up the harnesses:
- Both wanted to use yt-dlp by calling it through the command line. I had to refine the plan in both experiments to programmatically use the yt-dlp internals.
- Some clients append
.viewto the endpoints. Feishin did this while I was testing with it. A quick paste of the server logs was enough for both harnesses to resolve the issue.
Two other aspects that OpenCode handled just as well as Claude Code:
- When the harness doesn't have enough context I'll often paste a link to documentation and direct the tool to read review it. For example, the spec didn't cover the details of what a conformant implementation of
getOpenSubsonicExtensionsshould include, but the docs did. - When there are multiple options for an implementation and I don't have a strong opinion I will sometimes ask the harness to search the web for what is idiomatic. For example, when I added caching there are a couple different libraries I could use.
OpenCode UX vs Claude Code
The main difference between the two harnesses was not the performance, but the UX. The main differences I want to highlight are:
- No proper plan mode yet
- Asking vs Doing
- Getting OpenCode to use specific tools
- No built in memory yet
No proper plan mode yet
One huge problem for me is the lack of a tightly integrated plan mode. I really like the process of iterating on a written plan with the agent, and then changing modes to implement the plan. It feels more like the "centaur" scenario where automation helps you, rather than the "reverse centaur" scenario, where you are helping the machine.
Instead, in OpenCode you have two built-in agents by default: Plan and Build. Plan mode disables system tools for writing and provides a system prompt for planning. You can still shift+ctrl to cycle between modes, but the workflow is not as well developed.
One distinction is that Claude Code drafts the plan in a markdown file. OpenCode has a .opencode/plans/ directory that it can use for the same purpose, but I found that OpenCode never actually wrote out the plan and iterated on it. The written plan is especially important to enable the "Accept plan and clear context" functionality that Claude Code has. Context size is limited and clearing the context while keeping the written plan is a nice way to avoid context poisoning. There is an open issue with an in progress PR for adding the "Accept plan and clear context" functionality so I imagine OpenCode will get there one day.
Asking vs Doing
By default, Claude code assumes it cannot use tools and will ask you to use a tool the first time it tries to. You are then given the choice to allow it once, or always for that project. Claude scopes write permissions more granularly at the folder level.
On the other hand, for OpenCode's tools usage:
By default, all tools are enabled and don’t need permission to run. You can control tool behavior through permissions.
This is more of a philosophical difference than a technical one, but I find Claude Code better aligns with what I want. One of the reasons I like Claude Code more than tools like Cursor is the amount of control I retain. Now I should say, part of this difference is because of the tight coupling between Anthropic's models and Claude code. It is much harder to constrain tool use when you want to support any open model.
Some specific examples:
- OpenCode assumed we would stub the endpoints with no auth, Claude Code asked if should implement auth.
- Claude Code asked what should be done about IDs for artists, albums, and songs. OpenCode assumed I would just want to re-use the youtube music IDs.
- After the MVP I had to manually prod Claude Code to do some curl tests against the server. OpenCode tested with curl on its own.
In these specific examples, OpenCode happened to default to the choice I would have picked, but I would have preferred I was asked.
Thankfully, runtime permission models were added in Jan, though they are not currently persisted. There is an open issue to add persistence, which is very important to avoid approval fatigue. I am hopeful that OpenCode will continue to improve on this front, but it will take time.
Getting OpenCode to use Specific Tools
On the flip side, I had trouble getting OpenCode to consistently use tools. I really like using the AskUserQuestion in Claude Code when iterating on a design. OpenCode has a similar Question tool, but rarely used it. Even when I added a note in the agents file, or asked in a session to make sure to use the tool it often would not. I'm not sure if that was K2.6 specific.
Similarly, the OpenAPI spec in this project is big and I have jq installed to handle large JSON files. Claude Code will use that more or less automatically, but I had to prompt OpenCode to remember to use jq rather than writing a bespoke Python script every time.
No memory yet
All of those preceding issues wouldn't be a huge problem if I could use memory files or automemory like in Claude Code to iteratively guide OpenCodes behavior. However, OpenCode does not have built in support for memory yet. There is a plugin opencode-mem that may help, but this is essential enough functionality it would be nice to have by default. There is an open ticket that is assigned so hopefully we won't have to wait too long for this.
Other minor thoughts:
- I like that I can see all the reasoning prompts, Claude Code has started hiding reasoning unless you explicitly turn it back on.
- I like that by default I can see the context usage without having to install anything. In Claude Code I have to use ccstatusline.
- There is no double-escape to rewind like Claude Code, but I didn't need that for this test in particular. Looks like rewind was just merged this week though.
Closing thoughts
Bringing all these issues together, the gap between the two means that I feel like I have more agency when using Claude Code as it is right now than I do in OpenCode. Ironic, considering that I have less control on the model side with Claude Code. That's the whole reason I wanted to see if I could move off to OpenCode.
The gap is not insurmountable though. So, for a little while at least I've canceled my Anthropic subscription to give OpenCode more time. The best part is that when my discounted subscription ends, I can try out some more discounted models from other providers.
Ultimately, the demand problem for model providers does not seem to be going away any time soon. They will continue to over provision to acquire users, and then cut back when they scale up. I should note that during the experiment I got a number of:
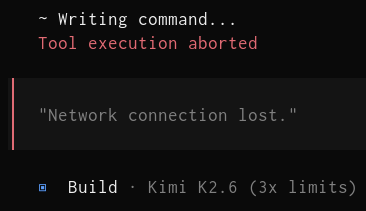
So I imagine OpenCode's hosted service is under the same scaling pressure if more people jump ship from Anthropic. I will keep a careful eye on how OpenCode handles this. The good news is that tools which supports interoperability are more guarded against service degradation. You can always choose to pick a different service provider. [5] Or better yet, if we're lucky the self-hostable models will get good enough that we will not need to run a hosted model for most tasks. We can instead use a hybrid approach where we default to local models first, and only pay for models on harder tasks.

Still a bummer that we can only get the weights rather than a truly open model. ↩︎
See this benchmark. ↩︎
I will say, I'm not a fan that I can only sign up with Google or GitHub oauth. ↩︎
Weirdly enough OpenCode wanted to use datamodel-code-generator to make the stubs, but eventually gave up on that. ↩︎
I know I will probably try a different provider once my one month discount ends for OpenCode Go. ↩︎
Member discussion