Using Self-hosting Language Models So You Can Evaluate Claude Code
I've avoided hopping on the AI hype train on this blog, but this topic is in line with what I usually write about for self-hosting. My work had a nice workshop that I want to write about. However, that requires using Claude Code and that in turn requires paying Anthropic money. So I first wanted to do a little guide on a self-hosted alternative for running a language model that works with Claude Code.
Normally, I self-host all my services on my Unraid server. I explicitly built it with no dedicated GPU to reduce power consumption. The Intel Core i5-13500 CPU I have is more than enough for video transcoding and surprisingly power efficient. Technically, for my self-hosted dog camera I also added a Coral Dual Edge TPU, but that also sips energy.
However, in my desktop I have a AMD Sapphire 7900 XT [1] so I will install everything for Claude code there. This works out well, because I do most of my personal projects on my desktop anyways and I don't need the model to always be available, only when I'm working. Additionally, I run NixOS on my desktop so I will share my nix configuration, but the ideas here will work more broadly.
Essentially all I need is:
- Something to run the model on.
- Something to make the model look like it's an Anthropic model.
- Some configuration changes for Claude Code.
On model choice
MiniMax M2 released last week, and on benchmarks it compares really well to Claude's official models. The model is also specifically designed for use in agentic coding. It is self-hostable in the sense that the weights are open, but the requirements state:
Memory requirements: 220 GB for weights, 240 GB per 1M context tokens
- 4x 96GB GPUs: Supported context length of up to 400K tokens.
- 8x 144GB GPUs: Supported context length of up to 3M tokens.
So self hosting is not particularly feasible. Especially since I am trying to be considerate of power usage. I think conceptualizing the requirements for these models is important for understanding just how much resources these tools are sucking up.
Additionally, Ollama does not even support MiniMax-M2 yet. The only supported inference options are SGLang, vLLM, and MLX. Of those MLX is Apple Silicon only. Of the remaining two, vLLM has better LiteLLM integration, but getting vLLM working is a giant can of worms currently.
So for models that could reasonably be run on a desktop single GPU, there's GPT-OSS 20B or Qwen3-Coder 30B which are both good options. I chose the later because of the larger context window, which will be relevant in the next post I make. Qwen is also nice since it uses Mixture-of-experts which reduces the number of active layers. Finally, Claude Code needs a model that supports tool calling which Qwen checks the box on.
Setting up Ollama
Ollama is a very quick and easy way to download and run language models. The NixOS wiki has a nice guide for Ollama.
In my case I added the following configuration:
services.ollama = {
enable = true;
loadModels = ["qwen3-coder:30b"];
acceleration = "rocm";
};
The example from the wiki uses cuda for acceleration, but I searched nixpkgs for the services.ollama.acceleration option and see that I can use "rocm" instead. Typically on Linux, AMD hardware will get better performance with a Vulkan backend, but Ollama only merged support last month and nixpkgs is still waiting to add support.
Also, note that I preloaded the Qwen model, but models can also be downloaded with:
$ ollama run qwen3-coder:30b
I do not use services.ollama.openFirewall since everything will run on the same machine.
With a nixos-rebuild I then should see:
❯ ollama list
NAME ID SIZE MODIFIED
qwen3-coder:30b 06c1097efce0 18 GB About a minute ago
LiteLLM Proxy Server setup
LiteLLM can be configured to work with ollama. [2] Additionally, LiteLLM provides a proxy server for models and NixOS supports running the proxy server as a service. I couldn't find a wiki entry for LiteLLM, but I found all the options using nixpkgs search.
Normally, the LiteLLM proxy settings are written in yaml:
model_list:
- model_name: "qwen3-coder"
litellm_params:
model: "ollama/qwen3-coder:30b"
api_base: http://localhost:11434
model_info:
supports_function_calling: true
On NixOS they can be set using services.litellm.settings. The settings field is a type "yaml 1.1 value" which maps into a nix attribute set. So I converted the above yaml into the following:
services.litellm = {
enable = true;
settings = {
model_list = [
{
model_name = "qwen3-coder";
litellm_params = {
model = "ollama/qwen3-coder:30b";
api_base = "http://localhost:11434";
model_info = {
supports_function_calling = true;
};
};
}
];
environment_variables = {
LITELLM_MASTER_KEY = "sk-1234";
};
};
};
Alternatively, I could have mapped the model to a Anthropic model name:
- model_name: claude-sonnet-4-20250514
litellm_params:
model: ollama/qwen3-coder
api_base: http://localhost:11434
Also, the default Ollama port on nixos is 11434.
Weirdly, the LiteLLM docs reference 8000 as the port for the web UI, but on NixOS the port defaults to 8080:
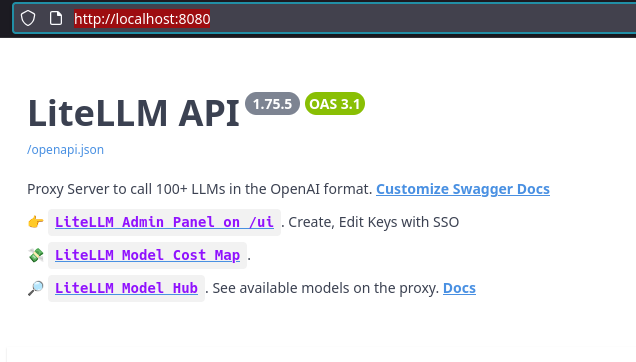
When I attempted to go to the admin panel I was redirected to http://localhost:8080/sso/key/generate. LiteLLM needs a master key set and above I used an example key, but any random string starting with "sk-" works. For example, openssl rand -hex 32 to generate an appropriate string.
Hitting the /models endpoint gets a response similar to:
{
"data": [
{
"id": "qwen3-coder",
"object": "model",
"created": 1677610602,
"owned_by": "openai"
}
],
"object": "list"
}
That confirms LiteLLM is configured with the Ollama model. The model can be tested quickly with: [3]
curl -X POST http://0.0.0.0:8080/v1/messages \-H "Authorization: Bearer $LITELLM_MASTER_KEY" \-H "Content-Type: application/json" \-d '{ "model": "qwen3-coder", "max_tokens": 1000, "messages": [{"role": "user", "content": "What is the capital of France?"}]}'
Claude Code Setup
All that's left now is to make Claude code work with the qwen. Claude Code has open issue for self hosting models. So until they support that I have to trick it into using the model. This works because LiteLLM will conform to the shape of Anthropic's Gateway API.
So after installing Claude Code or just adding the claude-code package on NixOS, I just needed to point it at LiteLLM:
export ANTHROPIC_BASE_URL="http://0.0.0.0:8080"
export ANTHROPIC_AUTH_TOKEN="$LITELLM_MASTER_KEY"
export ANTHROPIC_MODEL="qwen3-coder"
Now, there is a chance it may not work due to a a known bug. If that happens, OpenRouter could be used as an alternative.
Final thoughts
I'm not convinced that Claude Code or tools like it will be necessary for writing code in the future. However, I do think there is value in trying to evaluate new tools to figure that out for yourself. That way you can have a more informed opinion.
Normally, you would have to spend $20 to get a month's access to the models you would need to run Claude Code in order to do the evaluation. Self-hosting is a nice opportunity to just try it out and see how it goes. Even if the models you run locally aren't quite as good as the official ones.
Newegg somehow accidentally sent me this at one point, and never noticed... ↩︎
MiniMax-M2 support for LiteLLM was added last week if you are somehow able to run it.] ↩︎
This example is taken from the LiteLLM docs. ↩︎
Member discussion